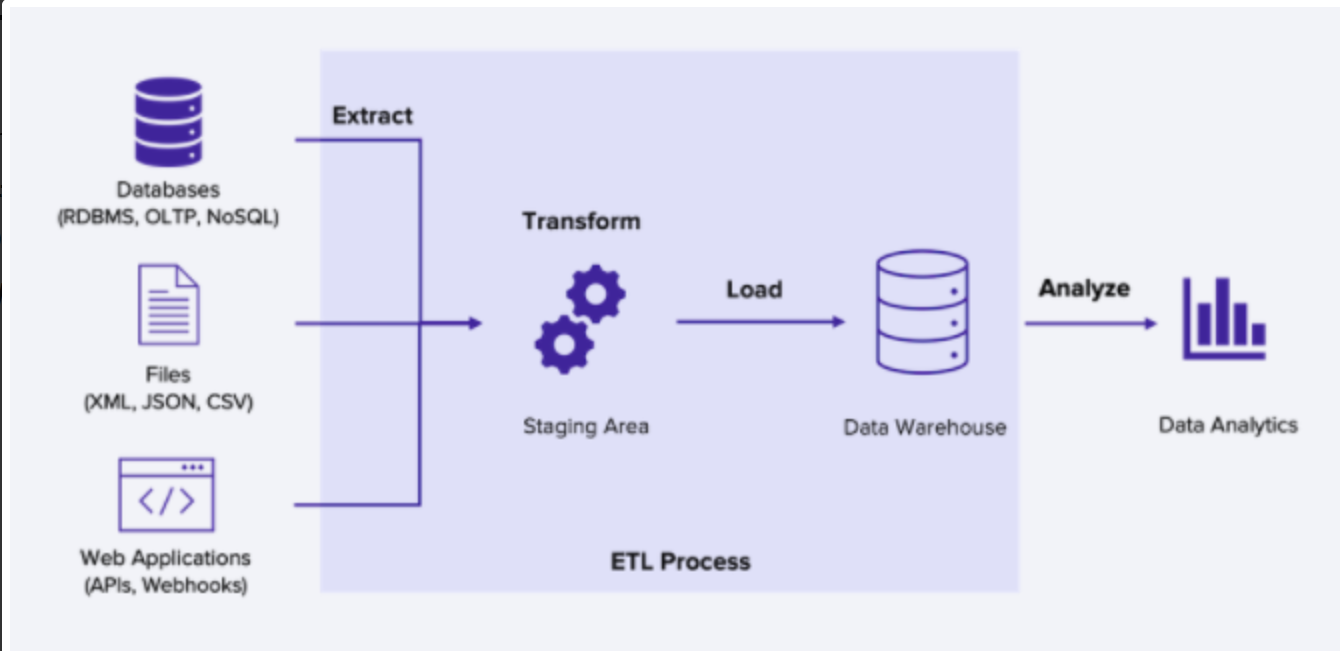
ETL 이란? Extract, Transform, Load
기업이 전 세계 모든 곳의 수많은 팀에서 관리하는 구조화된 데이터와 구조화되지 않은 데이터를 비롯한 전체 데이터를 가져와 비즈니스 목적에 실질적으로 유용한 상태로 변환하는 엔드 투 엔드 프로세스를 의미합니다.
여러가지 데이터 소스에서 추출 (Extract) 하고, 데이터를 원하는 형태로 변형 (Transform) 하고, Data Warehouse로 적재 (Load) 하는 과정입니다. 비즈니스 또는 분석 용도에 맞추어 데이터를 잘 정제하는 단계 (Transform) 가 중요하고, 데이터 크기가 클수록 Transform 하는 시간도 오래 걸린다. ETL 파이프라인이 설계된 후에는 1일 1회 등의 방식으로 업데이트 된 내용을 다시 가져와서 새로운 내용을 저장한다.
ELT 란? Extract, Load, Transform
데이터를 추출 (Extract) 하고, 적재 (Load) 를 먼저 진행한 후, 변형 (Transform) 하는 것이다. 모든 데이터 소스를 하나의 공간 (DataLake) 으로 적재한 뒤, 그 용도에 따라서 필요한 경우 툴이나 시스템이 직접 변형하게 하는 과정.

요새는 트렌드가 ETL 에서 ELT 로 바뀌고 있는데 그 이유는
[ 대량의 데이터 ] : Transform을 하는 시간 때문에 실시간 대규모 데이터를 처리하는 것이 어려워졌다. 그래서 우선 데이터를 다 저장하고, 이 데이터를 어떻게 쓸지는 나중에 고민해보는 식의 방식으로 변화했다.
여기서 생겨난 개념이 DataLake 이다. 마치 호수처럼 데이터 웨어하우스 앞단에 모든 데이터를 다 저장해두고 (DataLake), 그 중에 일부만 용도에 따라 데이터 웨어하우스로 가져가서 쓴다는 컨셉이다.
[ 리소스들의 가격 인하 ] : 기존엔 저장 공간이 부족해서 분석을 위한 CPU 성능도 부족해 미리 변환 / 정체를 해야했는데, 이제는 CPU, 메모리, SSD, HDD 등 리소스가 싸졌을 뿐만 아니라 클라우드 사용료도 인하 되고 있다. 그래서 차라리 이정도 가격이면 전부 다 저장해 버리는게 낫겠다는 컨샙애서 데이터를 먼저 저장하게 되었다.
Data Lake vs Data Warehouse
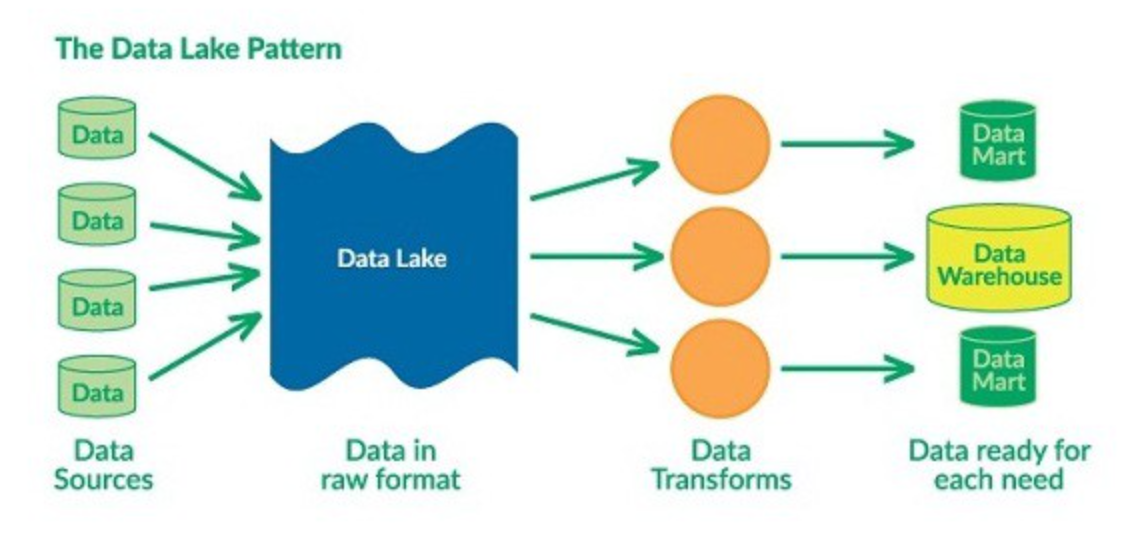
[ Data Warehouse ] : 어느 정도 가치가 있고, 구조화된 데이터들이 모여있는 곳. 다만 공간 제약이 있어서 필요한 모든 데이터를 저장하지는 않고 어느 정도 최근 데이터만 저장
[ Data Lake ] : Data Warehouse 기반 파이프라인 보다 훨씬 큰 개념. 구조화된 데이터도 있지만, 비 구조화된 데이터들이 존재한다. Data Warehouse 보다 용량도 크고 비용이 저렴해서 처음부터 현재까지 모든 데이터를 다 저장한다.
Data Lake에는 다양한 종류의 Raw Data가 시간 제약없이 들어있다. 따라서 Data Modeling을 하는 사람의 관점에서는 원하는 Features들이 Data Warehouse에는 없는 경우가 있기 때문에 Data Lake에서 찾아 사용할 수 있다.
Data Lake 중에서 의미가 있는 최신 데이터만 Transform 해서 Data Warehouse에 Load 된다. 보통 Data Lake에 있는 데이터가 너무 많기때문에 일반적인 Pandas를 가지고 처리하기는 어렵다. 따라서 분산 컴퓨팅 환경 (Spark, Redshift Spectrum, Athena) 등을 통해서 data transform을 진행한다. 이렇게 처리된 데이터들은 Data Warehouse나 Data Mart에 저장된다.
'DevOps > Google Cloud Platform' 카테고리의 다른 글
| SLI, SLO, and SLA in SRE에 대해 알아보자 (1) | 2022.12.16 |
|---|---|
| Cloud DNS에 대해 알아보자 (0) | 2022.12.05 |
| Cloud VPN에 대해 알아보자 (0) | 2022.11.28 |
| File Storage와 Block Storage에 대해 알아보자 (0) | 2022.10.10 |
| Virtual CPU (vCPU)에 대해 알아보자 (1) | 2022.10.05 |